![]()
Databricks-Machine-Learning-Professional Practice Test Questions Updated 193 Questions
Databricks Databricks-Machine-Learning-Professional Dumps - Secret To Pass in First Attempt
Databricks Databricks-Machine-Learning-Professional Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
| Topic 6 |
|
NEW QUESTION # 10
A machine learning engineer wants to log feature importance data from a CSV file at path importance_path with an MLflow run for model model.
Which of the following code blocks will accomplish this task inside of an existing MLflow run block?
A)
B)
C) mlflow.log_data(importance_path, "feature-importance.csv")
D) mlflow.log_artifact(importance_path, "feature-importance.csv")
E) None of these code blocks tan accomplish the task.
- A. Option A
- B. Option E
- C. Option B
- D. Option D
- E. Option C
Answer: A
NEW QUESTION # 11
What is the main purpose of the Databricks Feature Store?
- A. Centralizing reusable ML features
- B. Storing trained models
- C. Replacing Spark ML pipelines
- D. Storing raw data
Answer: A
Explanation:
Feature Store allows teams to:
share features
avoid training/serving skew
maintain feature lineage.
NEW QUESTION # 12
A Machine Learning Engineer uses Lakehouse Monitoring to track their credit scoring model's performance. The existing profile metrics table contains three aggregate metrics:
- adefault_risk_score
- payment_history_score
- credit_utilization_score
They need to:
1. Create a composite risk rating that combines these three scores using weights of 0.5, 0.3, and 0.2 respectively.
2. Monitor drift of this composite score against an established baseline.
Which approach should be used to implement both requirements within Lakehouse Monitoring?
- A. Create an aggregate metric for composite_risk_rating and configure a separate drift metric to monitor changes.
- B. Create a derived metric for the composite_risk_rating calculation and create a drift metric on this derived metric.
- C. Create two separate aggregate metrics: one for the composite score calculation and another for drift detection.
- D. Use a scheduled notebook to calculate the composite score and manually insert both the score and drift values into the profile metrics table.
Answer: B
Explanation:
Lakehouse Monitoring supports derived metrics that are computed from existing profile metrics using custom expressions. By defining a derived metric for the composite_risk_rating using the specified weights, the composite score becomes a first-class metric in the monitoring framework.
A drift metric can then be directly configured on this derived metric to compare current values against the baseline, fulfilling both the composite calculation and drift monitoring requirements in a native, governed way.
NEW QUESTION # 13
A machine learning engineering team wants to build a continuous pipeline for data preparation of a machine learning application. The team would like the data to be fully processed and made ready for inference in a series of equal-sized batches. Which tool can be used to provide this type of continuous processing?
- A. Structured Streaming
- B. MLflow
- C. Spark UDFs
- D. Delta Lake
Answer: C
NEW QUESTION # 14
A machine learning engineer and data scientist are working together to convert a batch deployment to an always-on streaming deployment. The machine learning engineer has expressed that rigorous data tests must be put in place as a part of their conversion to account for potential changes in data formats. Which of the following describes why these types of data type tests and checks are particularly important for streaming deployments?
- A. Because the streaming deployment is always on, there is a need to confirm that the deployment can autoscale
- B. None of these statements
- C. Because the streaming deployment is always on, there is no practitioner to debug poor model performance
- D. All of these statements
- E. Because the streaming deployment is always on, all types of data must be handled without producing an error
Answer: E
NEW QUESTION # 15
A Machine Learning Engineer is conducting hyperparameter tuning for multiple XGBoost models using Ray Tune on Databricks. They want to integrate MLflow tracking to monitor their experiments and need to ensure proper authentication. The engineer has Ray 2.41 installed and wants to use both Ray Tune and MLflow together in their distributed tuning workflow. They have to configure Databricks to run the hyperparameter optimization with MLflow integration. Which set of configuration steps will do this?
- A. Configure DATABRICKS_HOST and DATABRICKS_TOKEN environment variables before calling setup_ray_cluster().
- B. Enable MLflow autologging with mlflow.ray.autolog() and set the tracking server URI.
- C. Set MLFLOW_TRACKING_URI and MLFLOW_EXPERIMENT_TD environment variables before initializing Ray.
- D. Install the MLflow Ray plugin using %pip install mlflow-ray and configure the workspace connection.
Answer: A
Explanation:
When using Ray Tune with MLflow on Databricks, Ray workers must be able to authenticate back to the Databricks workspace to log runs to MLflow Tracking. Setting the DATABRICKS_HOST and DATABRICKS_TOKEN environment variables before initializing the Ray cluster ensures all Ray processes can securely communicate with Databricks and correctly log MLflow experiments during distributed hyperparameter tuning.
NEW QUESTION # 16
Which MLflow component is used to log parameters, metrics, and artifacts during model training?
- A. MLflow Tracking
- B. Model Registry
- C. MLflow Models
- D. MLflow Projects
Answer: A
Explanation:
MLflow Tracking records experiment runs including:
parameters
metrics
artifacts (models, plots, etc.)
NEW QUESTION # 17
A machine learning engineer has deployed a model recommender using MLflow Model Serving.
They now want to query the version of that model that is in the Production stage of the MLflow Model Registry. Which of the following model URls can be used to query the described model version?
- A. https:///model/recommender/stage-production/invocations
- B. https:///model-serving/recommender/Production/invocations
- C. The version number of the model version in Production is necessary to complete this task.
- D. https:///model/recommender/Production/invocations
Answer: D
Explanation:
In MLflow Model Serving, the correct URL pattern to query a specific stage of a registered model is https:///model/<model_name>/<stage>/invocations Thus, to query the model named recommender in the Production stage, the proper endpoint is
https:///model/recommender/Production/invocations.
This allows direct access to the active production version without needing its version number.
NEW QUESTION # 18
A machine learning engineer is migrating a machine learning pipeline to use Databricks Machine Learning. They have programmatically identified the best run from an MLflow Experiment and stored its URI in the model_uri variable and its Run ID in the run_id variable. They have also determined that the model was logged with the name "model". Now, the machine learning engineer wants to register that model in the MLflow Model Registry with the name "best_model".
Which line of code can they use to register the model to the MLflow Model Registry?
- A. mlflow.register_model(f"runs:/{run_id}/model")
- B. mlflow.register_model(run_id, "best_model")
- C. mlflow.register_model(f"runs:/{run_id}/best_model", "model")
- D. mlflow.register_model(model_uri, "best_model")
- E. mlflow.register_model(model_uri, "model")
Answer: D
NEW QUESTION # 19
A machine learning engineer has developed the following custom model class with preprocessing logic to combine two columns: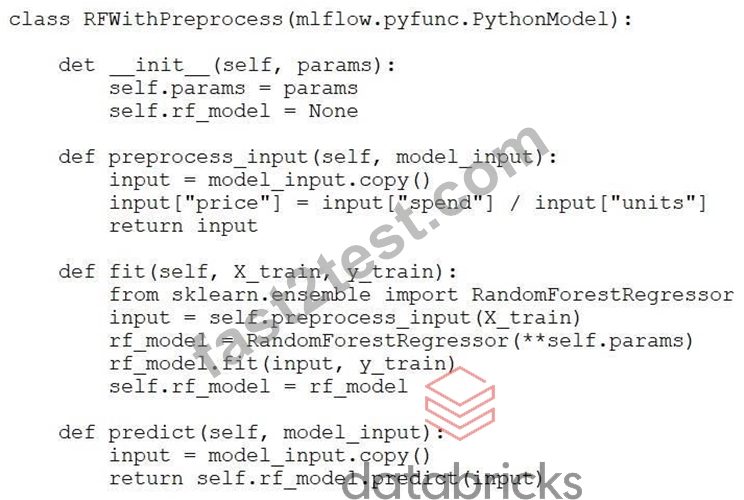
However, instances of this class are unable to compute predictions.
Which set of changes will update the class so predictions can be computed while continuing to apply the preprocessing logic?
- A. Replace model_input.copy() with self.preprocess_input(model_input.copy()) in the preprocess_input method
- B. Remove the self.rf_model = rf_model line from the fit method
- C. Replace self.rf_model.predict(input) with self.predict(input) in the predict method
- D. Replace model_input.copy() with self.preprocess_input(model_input.copy()) in the predict method
Answer: D
Explanation:
The issue is that the predict() method does not apply the same preprocessing as the fit() method.
During training, the model uses preprocessed data (via self.preprocess_input()), but during prediction, it directly uses raw input. This mismatch causes prediction errors because the model expects preprocessed input.
By updating the predict() method to call self.preprocess_input(model_input.copy()), both training and prediction use consistent feature transformations, allowing predictions to be computed successfully.
NEW QUESTION # 20
A data scientist has developed a model model and computed the RMSE of the model on the test set. They have assigned this value to the variable rmse. They now want to manually store the RMSE value with the MLflow run.
They write the following incomplete code block:
Which of the following lines of code can be used to fill in the blank so the code block can successfully complete the task?
- A. There is no way to store values like this.
- B. log_model
- C. log_artifact
- D. log_param
- E. log_metric
Answer: C
NEW QUESTION # 21
A Data Scientist is building a product recommendation model that suggests additional items based on a customer's current shopping basket for an online merchant. The model needs to access the real-time basket contents at inference time to avoid recommending items already in the basket. The model will be deployed using Databricks Model Serving. The data scientist now wants to implement real-time feature engineering to incorporate the current basket contents into the model's prediction. Which approach will do this?
- A. Write basket data to a feature table and publish to the online store for low-latency access.
- B. Implement feature preprocessing in a separate microservice that feeds the model serving endpoint.
- C. Create a custom pyfunc model that processes the basket contents as part of the model's predict() method.
- D. Store basket data in a Delta table and configure automatic feature lookup during model serving.
Answer: C
Explanation:
Real-time basket contents are request-specific and only available at inference time, making them unsuitable for precomputed feature tables or online stores. Implementing a custom pyfunc model allows the predict() method to directly consume and process the basket contents included in the request payload, enabling real-time feature engineering while keeping the logic tightly coupled with model inference in Databricks Model Serving.
NEW QUESTION # 22
Which of the following lists all of the model stages are available in the MLflow Model Registry?
- A. None. Staging. Production. Archived
- B. None. Staging. Production
- C. Staging. Production. Archived
- D. Development. Staging. Production
- E. Development. Staging. Production. Archived
Answer: D
NEW QUESTION # 23
A Data Scientist has created a sales forecasting model, named sales-forecasting. The model is deployed to a model serving endpoint with a schema. They need to invoke this model using Python and would prefer to use a SDK function to make the request. Which method suits these requirements?
- A. Import the MLflow Deployments class and use the ai_query method and provide the endpoints and request parameters.
- B. Import the MLflow Deployments class and use the predict method and provide the endpoint and input parameters.
- C. Use the built in ai_query function and provide the endpoints and request parameters.
- D. Make an API request to the MODEL_VERSION_URI and provide the dataframe_split as the request parameter.
Answer: B
Explanation:
The MLflow Deployments SDK provides a predict method specifically designed to invoke Databricks model serving endpoints from Python. This method abstracts the HTTP request details, allows specifying the endpoint name directly, and cleanly passes input parameters that conform to the model's serving schema, making it the preferred SDK-based approach.
NEW QUESTION # 24
A data scientist has computed updated feature values for all primary key values stored in the Feature Store table features. In addition, feature values for some new primary key values have also been computed. The updated feature values are stored in the DataFrame features_df. They want to replace all data in features with the newly computed data.
Which of the following code blocks can they use to perform this task using the Feature Store Client fs?
- A.

- B.

- C.

- D.

- E.

Answer: E
NEW QUESTION # 25
......
Databricks Databricks-Machine-Learning-Professional Exam Dumps [2026] Practice Valid Exam Dumps Question: https://www.fast2test.com/Databricks-Machine-Learning-Professional-premium-file.html
Databricks-Machine-Learning-Professional Dumps - Grab Out For [NEW-2026] Databricks Exam: https://drive.google.com/open?id=1qemZEP4e5-JBYGU6T4KzaAZisx3HPW7R